The streaming percentiles library is a cross-platform, multi-language
(C++ and JavaScript) implementation of a number of online (single-pass)
percentile algorithms. This version of the streaming percentiles library
adds support for copy construction, assignment, move construction, and
move assignment on all analytics classes.
This change allows you to put streaming analytics classes into STL containers,
such as:
1
2
3
4
5
6
7
8
9
10
11
12
13
#include<vector>#include<stmpct/gk.hpp>std::vector<stmpct::gk<double>> algs;
algs.emplace_back(0.01);
algs.emplace_back(0.05);
for (auto&g : algs) {
for (int i =0; i <1000; ++i) {
g.insert(rand());
}
double p95 = g.quantile(0.95); // Approx. 95th percentile for current epsilon
}
It also allows you to efficiently move the state of an algorithm
from one object to another without copying, as in:
Versions 1.x and 2.x of the C++ library required all measurements to use the type double,
and usage of the algorithms looked something like this:
1
2
3
4
5
6
7
8
#include<stmpct/gk.hpp>double epsilon =0.1;
stmpct::gk g(epsilon);
for (int i =0; i <1000; ++i)
g.insert(rand());
double p50 = g.quantile(0.5); // Approx. median
double p95 = g.quantile(0.95); // Approx. 95th percentile
For version 3.x of the library, I have modified the algorithms to be
parameterized by type so that they are not limited to double. The
algorithms now may be used by type which implements a few simple
requirements: it must be default constructible, copy constructible,
assignable, and implement operator<. This means that they can now
be used with float, int, long double, a custom number type, or
even std::string.
I have decided to move my link aggregation efforts, such as they are, to Bitly, and to leave this blog for original content. Follow me on Twitter if you’re interested in tracking these links in the future.
In a previous blog post, I described how I took Emscripten-created JS and turned it into an UMD module. One of the reasons I did this was because I wanted more control over the generated JavaScript and for it to be usable in more contexts, such as with the RequireJS module loader.
As I am a responsible developer, I desired to create a number of automated unit tests to ensure that the client-visible API for my Emscripten module works as I intended. I began by searching for a browser automated test framework and settled upon Nightwatch.js. Now I just had to figure out how to get Nightwatch.js tests running in my existing, CMake-based build system. Here’s how I did it.
By default, Emscripten creates a module which can be used from both Node.JS and the browser, but it has the following issues:
The module pollutes the global namespace
The module is created with the name Module (in my case, I require streamingPercentiles)
The module cannot be loaded by some module loaders such as require.js
While the above issues can (mostly) be corrected by using –s MODULARIZE=1, it changes the semantics of the resulting JavaScript file, as the module now returns a function rather than an object. For example, code which previously read var x = new Module.Klass() would become var x = new Module().Klass(). I found this semantic change unacceptable, so I decided to abandon Emscripten’s -s MODULARIZE=1 option in favor of hand-crafting a UMD module.
Playing board games is a major hobby of mine. Every year I look forward to attending Gen Con, where I aggressively shop the dings and dents section of CoolStuffInc and play as many new games as I can.
We enjoy playing board games as a family. I’ve been playing board games with my daughter since she was four; she’s eight now, and quite the gamer. One of the things we’ve learned is that the recommended age range on a board game is merely a recommendation: the only real challenge for my daughter in playing advanced games was how well she was able to read.
This is part 7/8 of my Calculating Percentiles on Streaming Data series.
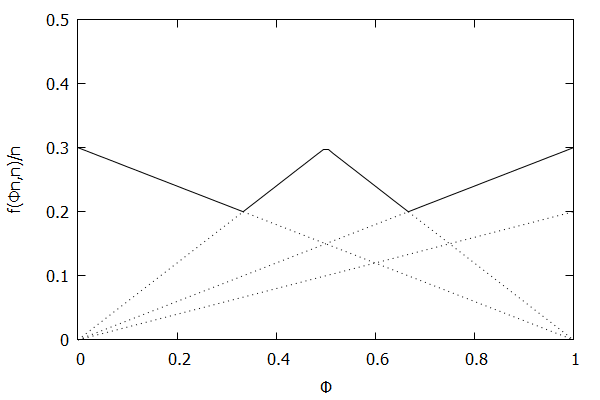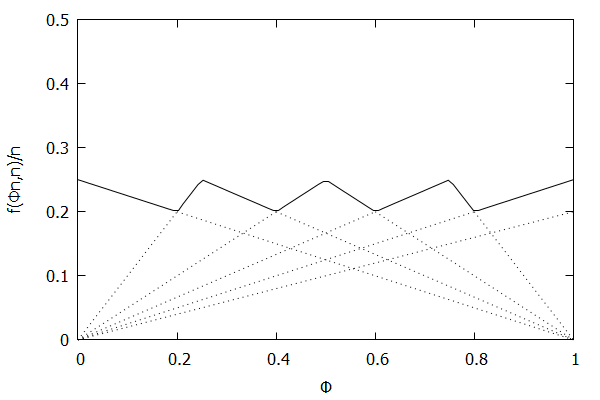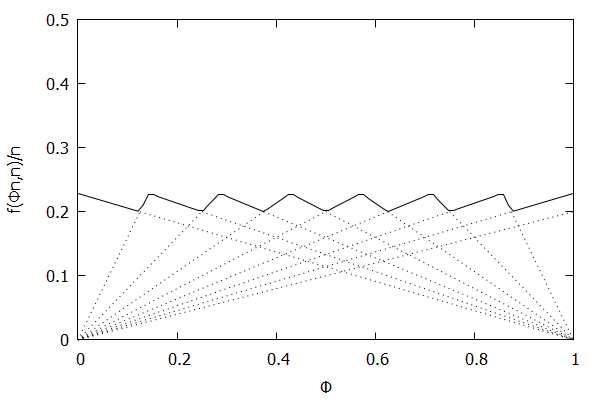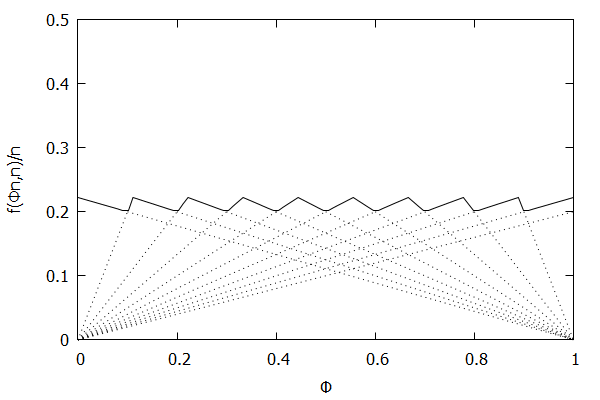
In 2005, Graham Cormode, Flip Korn, S. Muthukrishnan, and Divesh Srivastava published a paper called Effective Computation of Biased Quantiles over Data Streams [CKMS05]. This paper took the Greenwald-Khanna algorithm [GK01] and made the following notable changes:
Generalized the algorithm to work with arbitrary targeted quantiles, where a targeted quantile is a combination of a quantile $\phi$ and a maximum allowable error $\epsilon$. The algorithm will maintain the summary data structure $\mathsf{S}$ such that it will maintain each targeted quantile with the appropriate error rate.
Simplified the Compress() operation by removing the concept of banding.
The paper also demonstrated that the new, more generalized algorithm could handle the following cases with ease:
This is part 6/8 of my Calculating Percentiles on Streaming Data series.
For the past 10 days or so, I’ve been working on the build process of my C++ and JavaScript streaming analytics libraries. Using the magic of Emscripten, I have been able to combine both libraries into a single, C++ codebase, from which I can compile both the C++ and JavaScript versions of the library. Furthermore, I was able to do this without breaking backwards compatibility of the JavaScript library. I also made a number of other improvements to the compilation process, such as providing precompiled binaries and supporting both shared and static libraries.
This is part 5/8 of my Calculating Percentiles on Streaming Data series.
I have created a reusable C++ library which contains my implementation of the streaming percentile algorithms found within this blog post and published it to GitHub. Here’s what using it looks like:
1
2
3
4
5
6
7
8
9
10
#include<stmpct/gk.hpp>usingnamespace stmpct;
double epsilon =0.1;
gk g(epsilon);
for (int i =0; i <1000; ++i)
g.insert(rand());
double p50 = g.quantile(0.5); // Approx. median
double p95 = g.quantile(0.95); // Approx. 95th percentile
This is part 4/8 of my Calculating Percentiles on Streaming Data series.
I have created a reusable JavaScript library which contains my implementation of the streaming percentile algorithms found within this blog post and published it to GitHub and NPM. Here’s what using it looks like:
1
2
3
4
5
6
7
8
9
10
11
var sp = require("streaming-percentiles');
// epsilon is allowable error. As epsilon becomes smaller, the
// accuracy of the approximations improves, but the class consumes
// more memory.
var epsilon =0.1;
var gk =new sp.GK(epsilon);
for (var i =0; i <1000; ++i)
gk.insert(Math.random());
var p50 = gk.quantile(0.5); // Approx. median
var p95 = gk.quantile(0.95); // Approx. 95th percentile