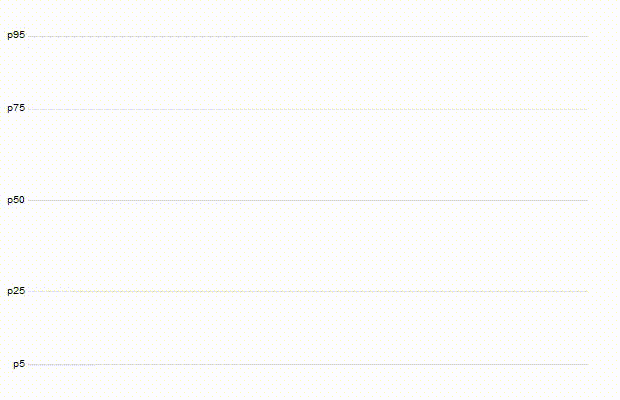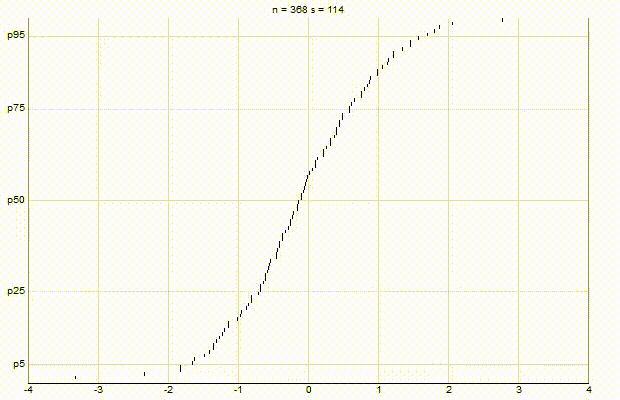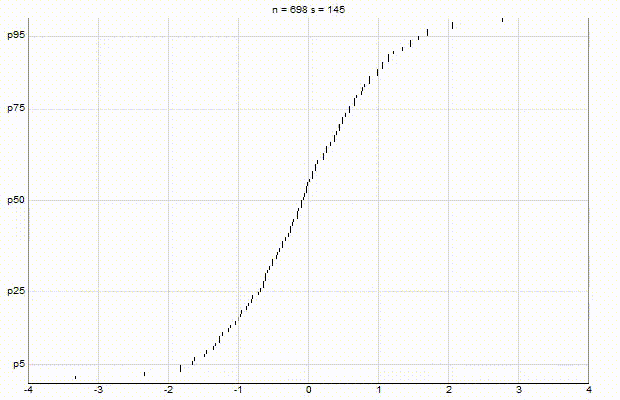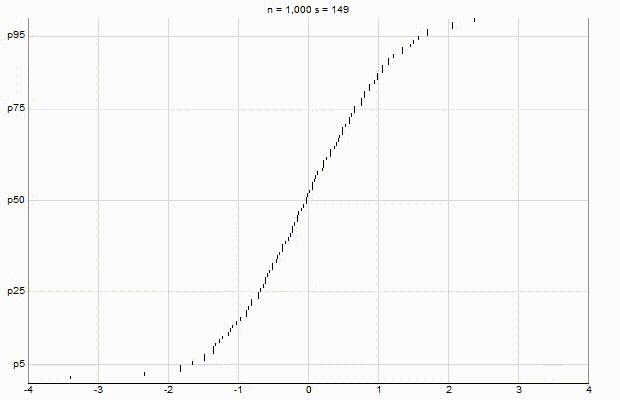The streaming percentiles library is a cross-platform, multi-language
(C++ and JavaScript) implementation of a number of online (single-pass)
percentile algorithms. This version of the streaming percentiles library
adds support for copy construction, assignment, move construction, and
move assignment on all analytics classes.
This change allows you to put streaming analytics classes into STL containers,
such as:
1
2
3
4
5
6
7
8
9
10
11
12
13
#include<vector>#include<stmpct/gk.hpp>std::vector<stmpct::gk<double>> algs;
algs.emplace_back(0.01);
algs.emplace_back(0.05);
for (auto&g : algs) {
for (int i =0; i <1000; ++i) {
g.insert(rand());
}
double p95 = g.quantile(0.95); // Approx. 95th percentile for current epsilon
}
It also allows you to efficiently move the state of an algorithm
from one object to another without copying, as in:
Versions 1.x and 2.x of the C++ library required all measurements to use the type double,
and usage of the algorithms looked something like this:
1
2
3
4
5
6
7
8
#include<stmpct/gk.hpp>double epsilon =0.1;
stmpct::gk g(epsilon);
for (int i =0; i <1000; ++i)
g.insert(rand());
double p50 = g.quantile(0.5); // Approx. median
double p95 = g.quantile(0.95); // Approx. 95th percentile
For version 3.x of the library, I have modified the algorithms to be
parameterized by type so that they are not limited to double. The
algorithms now may be used by type which implements a few simple
requirements: it must be default constructible, copy constructible,
assignable, and implement operator<. This means that they can now
be used with float, int, long double, a custom number type, or
even std::string.
At various points in my career, I have created or managed systems which
need to perform calculations on enormous amounts of numeric data in
real-time. Whether I was running a Varnish cluster that served
30,000 requests per second or writing financial analytics which needed
to calculate aggregates on terabytes of price and return data in a few
seconds, a common need emerged: how can I calcalate aggregates on
large amounts of numeric data in a single pass?
This is part 7/8 of my Calculating Percentiles on Streaming Data series.
In 2005, Graham Cormode, Flip Korn, S. Muthukrishnan, and Divesh Srivastava published a paper called Effective Computation of Biased Quantiles over Data Streams [CKMS05]. This paper took the Greenwald-Khanna algorithm [GK01] and made the following notable changes:
Generalized the algorithm to work with arbitrary targeted quantiles, where a targeted quantile is a combination of a quantile $\phi$ and a maximum allowable error $\epsilon$. The algorithm will maintain the summary data structure $\mathsf{S}$ such that it will maintain each targeted quantile with the appropriate error rate.
Simplified the Compress() operation by removing the concept of banding.
The paper also demonstrated that the new, more generalized algorithm could handle the following cases with ease:
This is part 6/8 of my Calculating Percentiles on Streaming Data series.
For the past 10 days or so, I’ve been working on the build process of my C++ and JavaScript streaming analytics libraries. Using the magic of Emscripten, I have been able to combine both libraries into a single, C++ codebase, from which I can compile both the C++ and JavaScript versions of the library. Furthermore, I was able to do this without breaking backwards compatibility of the JavaScript library. I also made a number of other improvements to the compilation process, such as providing precompiled binaries and supporting both shared and static libraries.
This is part 5/8 of my Calculating Percentiles on Streaming Data series.
I have created a reusable C++ library which contains my implementation of the streaming percentile algorithms found within this blog post and published it to GitHub. Here’s what using it looks like:
1
2
3
4
5
6
7
8
9
10
#include<stmpct/gk.hpp>usingnamespace stmpct;
double epsilon =0.1;
gk g(epsilon);
for (int i =0; i <1000; ++i)
g.insert(rand());
double p50 = g.quantile(0.5); // Approx. median
double p95 = g.quantile(0.95); // Approx. 95th percentile
This is part 4/8 of my Calculating Percentiles on Streaming Data series.
I have created a reusable JavaScript library which contains my implementation of the streaming percentile algorithms found within this blog post and published it to GitHub and NPM. Here’s what using it looks like:
1
2
3
4
5
6
7
8
9
10
11
var sp = require("streaming-percentiles');
// epsilon is allowable error. As epsilon becomes smaller, the
// accuracy of the approximations improves, but the class consumes
// more memory.
var epsilon =0.1;
var gk =new sp.GK(epsilon);
for (var i =0; i <1000; ++i)
gk.insert(Math.random());
var p50 = gk.quantile(0.5); // Approx. median
var p95 = gk.quantile(0.95); // Approx. 95th percentile
This is part 3/8 of my Calculating Percentiles on Streaming Data series.
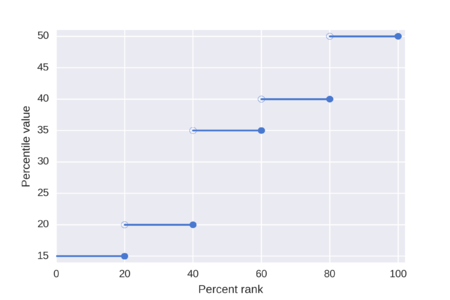
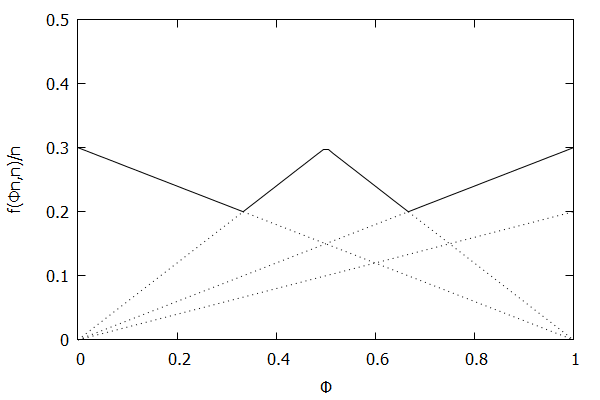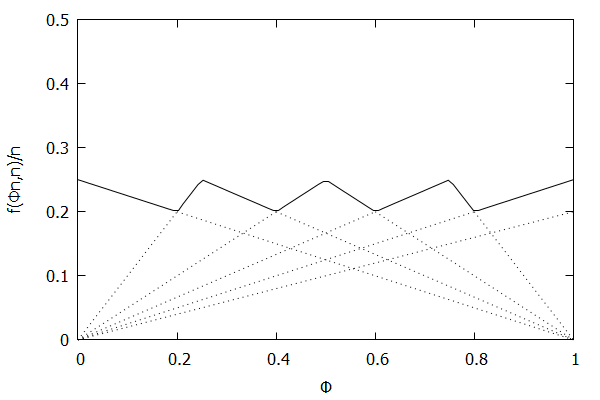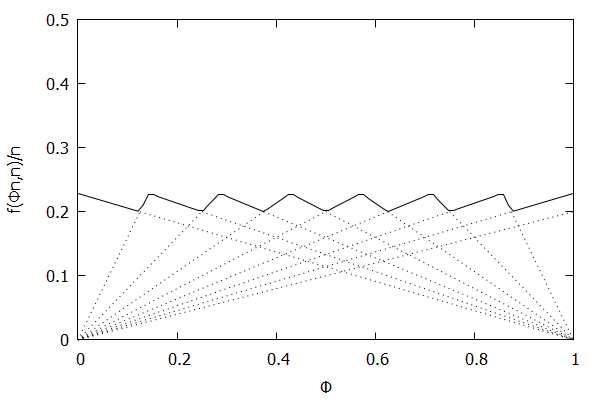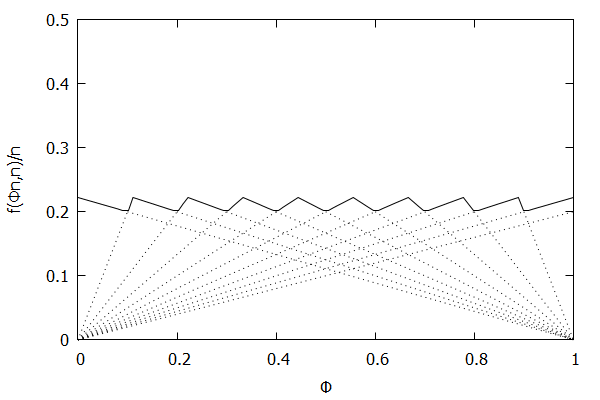
In an effort to better understand the Greenwald-Khanna [GK01] algorithm, I created a series of visualizations of the cumulative distribution functions of a randomly-generated, normally-distributed data set with $\mu$ = 0 and $\sigma$ = 1, as the number of random numbers $n$ increases from 1 to 1,000.
The way to read these visualizations is to find the percentile you are looking for on the y-axis, then trace horizontally to find the vertical line on the chart which intersects this location, then read the value from the x-axis.
This is part 2/8 of my Calculating Percentiles on Streaming Data series.
The most famous algorithm for calculating percentiles on streaming data appears to be Greenwald-Khanna [GK01]. I spent a few days implementing the Greenwald-Khanna algorithm from the paper and I discovered a few things I wanted to share.
Insert Operation
The insert operation is defined in [GK01] as follows:
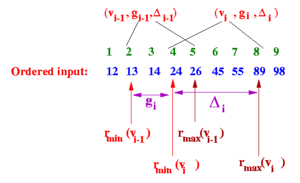
INSERT($v$)
Find the smallest $i$, such that $v_{i-1} \leq v < v_i$, and insert the tuple $ t_x = (v_x, g_x, \Delta_x) = (v, 1, \lfloor 2 \epsilon n \rfloor) $, between $t_{i-1}$ and $t_i$. Increment $s$. As a special case, if $v$ is the new minimum or the maximum observation seen, then insert $(v, 1, 0)$.
However, when I implemented this operation, I noticed via testing that there were certain queries I could not fulfill. For example, consider applying Greenwald-Khanna with $\epsilon = 0.1$ to the sequence of values ${11, 20, 18, 5, 12, 6, 3, 2}$, and then apply QUANTILE($\phi = 0.5$). This means that $r = \lceil \phi n \rceil = \lceil 0.5 \times 8 \rceil = 4$ and $\epsilon n = 0.1 \times 8 = 0.8$. There is no $i$ that satisfies both $r – r_{min}(v_i) \leq \epsilon n$ and $r_{max}(v_i) – r \leq \epsilon n$, as you can see below:
This is part 1/8 of my Calculating Percentiles on Streaming Data series.
Suppose that you are dealing with a system which processes one million requests per second, and you’d like to calculate the median percentile response time over the last 24 hours.
The naive approach would be to store every response time, sort them all, and then return the value in the middle. Unfortunately, this approach would require manipulating 1,000,000 * 60 * 60 * 24 = 86.4 billion values – almost certainly too many to fit into RAM, and thus rather unwieldy to work with. This begs the question “Is it possible to compute quantiles without storing every observation?”