I’d like to call out this particular assertion made by him way back in 2010:
[D]evelopers must move towards single-threaded programming models connected through message passing, optionally with provably race-free fine-grained parallelism inside of those single-threaded worlds.
Add “async/await everywhere” and you can sign me up!
Here’s why I try to avoid thread-based programming models for expressing concurrency:
The opponents of thread-based systems line up several drawbacks. For Ousterhout, who probably published the most well-known rant against threads [Ous96], the extreme difficulty of developing correct concurrent code–even for programming experts–is the most harmful trait of threads. As soon as a multi-threaded system shares a single state between multiple threads, coordination and synchronization becomes an imperative. Coordination and synchronization requires locking primitives, which in turn brings along additional issues. Erroneous locking introduces deadlocks or livelocks, and threatens the liveness of the application. Choosing the right locking granularity is also source of trouble. Too coarse locks slow down concurrent code and lead to degraded sequential execution. By contrast, too fine locks increase the danger of deadlocks/livelocks and increase locking overhead. Concurrent components based on threads and locks are not composable. Given two different components that are thread-safe, a composition of them is not thread-safe per se. For instance, placing circular dependencies between multi-threaded components unknowingly can introduce severe deadlocks.
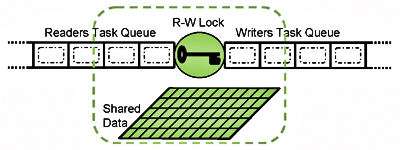
A reader-writer lock is a lock which will allow multiple concurrent readers but only one writer. A reader-writer lock can be significantly more efficient than a standard mutex if reads on your shared memory far outnumber writes.
Reader-writer locks naturally fit together with caches, as caches are only effective if reads far outnumber writes.
Here is a general pattern for using a reader-writer lock with a cache:
Acquire a reader lock.
Check the cache for the value. If it exists, save the value and go to step 8.
Upgrade the reader lock to a writer lock.
Check the cache for the value. If it exists, save the value and go to step 7.
Calculate the value (expensive, otherwise we wouldn’t cache it)
Insert the value into the cache.
Release the writer lock.
Release the reader lock.
Return the value.
The reason why we have to check the cache for the value again in step (4) is because of the following possibility (assume step 4 doesn’t exist):