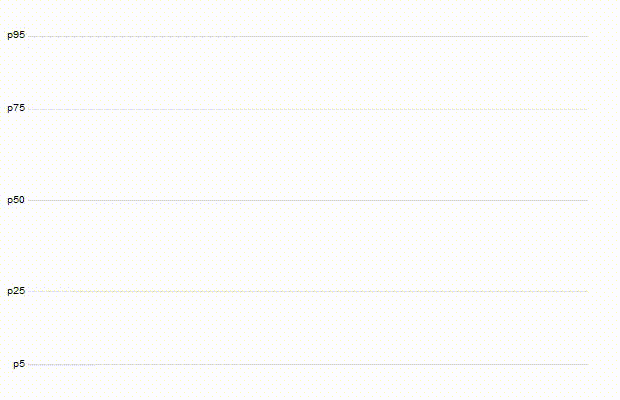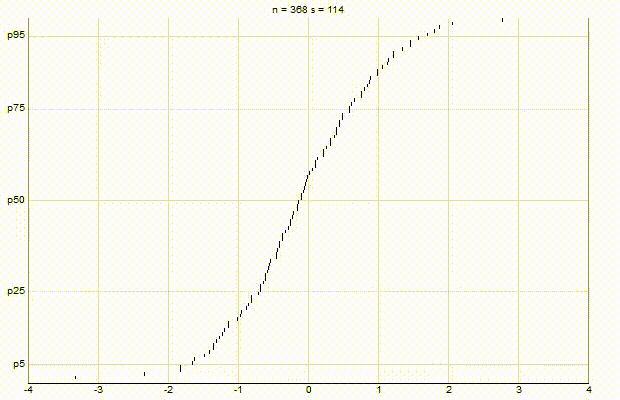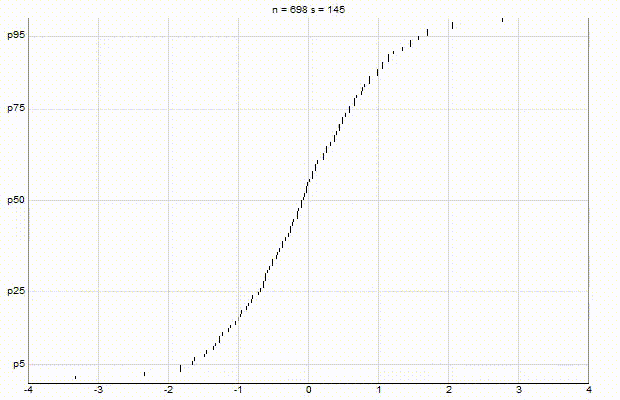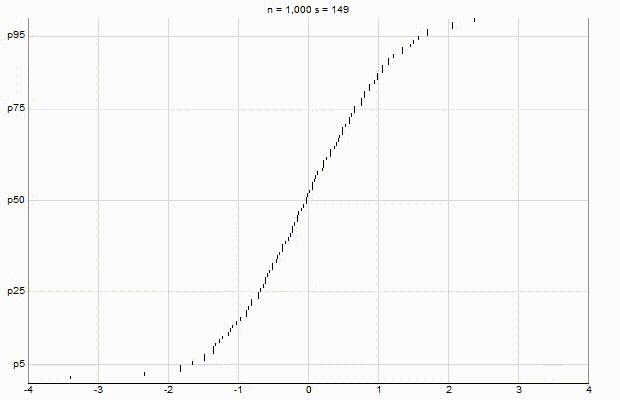This is part 3/8 of my Calculating Percentiles on Streaming Data series.
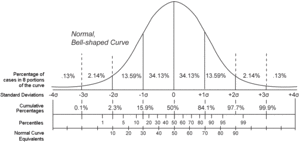
In an effort to better understand the Greenwald-Khanna [GK01] algorithm, I created a series of visualizations of the cumulative distribution functions of a randomly-generated, normally-distributed data set with $\mu$ = 0 and $\sigma$ = 1, as the number of random numbers $n$ increases from 1 to 1,000.
The way to read these visualizations is to find the percentile you are looking for on the y-axis, then trace horizontally to find the vertical line on the chart which intersects this location, then read the value from the x-axis.
This is part 2/8 of my Calculating Percentiles on Streaming Data series.
The most famous algorithm for calculating percentiles on streaming data appears to be Greenwald-Khanna [GK01]. I spent a few days implementing the Greenwald-Khanna algorithm from the paper and I discovered a few things I wanted to share.
Insert Operation
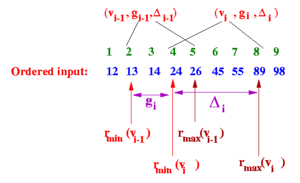
The insert operation is defined in [GK01] as follows:
INSERT($v$)
Find the smallest $i$, such that $v_{i-1} \leq v < v_i$, and insert the tuple $ t_x = (v_x, g_x, \Delta_x) = (v, 1, \lfloor 2 \epsilon n \rfloor) $, between $t_{i-1}$ and $t_i$. Increment $s$. As a special case, if $v$ is the new minimum or the maximum observation seen, then insert $(v, 1, 0)$.
However, when I implemented this operation, I noticed via testing that there were certain queries I could not fulfill. For example, consider applying Greenwald-Khanna with $\epsilon = 0.1$ to the sequence of values ${11, 20, 18, 5, 12, 6, 3, 2}$, and then apply QUANTILE($\phi = 0.5$). This means that $r = \lceil \phi n \rceil = \lceil 0.5 \times 8 \rceil = 4$ and $\epsilon n = 0.1 \times 8 = 0.8$. There is no $i$ that satisfies both $r – r_{min}(v_i) \leq \epsilon n$ and $r_{max}(v_i) – r \leq \epsilon n$, as you can see below:
This is part 1/8 of my Calculating Percentiles on Streaming Data series.
Suppose that you are dealing with a system which processes one million requests per second, and you’d like to calculate the median percentile response time over the last 24 hours.
The naive approach would be to store every response time, sort them all, and then return the value in the middle. Unfortunately, this approach would require manipulating 1,000,000 * 60 * 60 * 24 = 86.4 billion values – almost certainly too many to fit into RAM, and thus rather unwieldy to work with. This begs the question “Is it possible to compute quantiles without storing every observation?”
This post is part 4/4 of my Visualizing Latency series.
Allow me to wrap up my visualizing latency post series by noting that my official D3 latency heatmap repository is at https://github.com/sengelha/d3-latency-heatmap/. Monitor this repository for future developments to the D3 latency heatmap chart.
First, I must explain what I mean by event data. For a fuller treatment, please read Analytics For Hackers: How To Think About Event Data, but allow me to summarize: Event data describes actions performed by entities. It has three key pieces of information: action, timestamp, and state. It is typically rich, denormalized, nested, schemaless, append-only, and frequently extremely large. Some examples of event data include system log records, financial market trades, crime records, or user activities within an application.
This post is part 2/4 of my Visualizing Latency series.
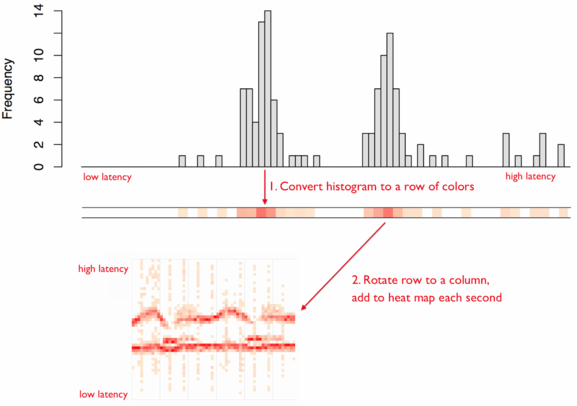
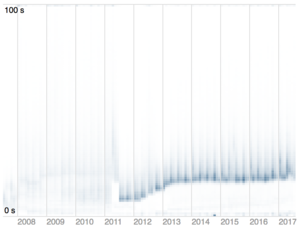
As mentioned in Brendan Gregg’s Latency Heat Maps page, a latency heat map is a visualization where each column of data is a histogram of the observations for that time interval. Using Brendan Gregg’s visualization:
As with histograms, the key decision that needs to be made when using a latency heat map is how to bin the data. Binning is the process of dividing the entire range of values into a series of intervals and then counting how many values fall into each interval. That said, there is no “best” number of bins, and different bin sizes can reveal different features of the data. Ultimately, the number of bins depends on the distribution of your data set as well as the size of the rendering area.
On the right, you can see a latency heatmap generated from a job queueing system which shows a number of interesting properties, not least of which is that the system appears to be getting slower over time.
This post is part 5/5 of my Data-Driven Code Generation of Unit Tests series.
In the previouspostsinthis series, I walked through the idea of performing data-driven code generation for unit tests, as well as how I implemented it in three different programming languages and build systems. This post contains some final thoughts about the effort.
Was it worth it?
Almost certainly. Although it required substantial up-front effort to set up the unit test generators, this approach found numerous, previously-undetected bugs both within my implementation of the calculation library as well as with legacy implementations. It is straightforward to write code generators that test all possible combinations of parameters to the calculations, ensuring that the resulting code coverage is excellent. Adding tests for a new calculation is as straightforward as adding a line to a single file.
As mentioned in Part 2: C++, CMake, Jinja2, Boost, all performance analytics metadata is stored in a single file called metadata.csv. This file drives all code generation and is what helps ensure inter-platform consistency.
This post is part 3/5 of my Data-Driven Code Generation of Unit Tests series.
This blog post explains how I used Java, Apache Maven, StringTemplate, and JUnit to perform data-driven code generation of unit tests for a financial performance analytics library. If you haven’t read it already, I recommend starting with Part 1: Background.
As mentioned in Part 2: C++, CMake, Jinja2, Boost, all performance analytics metadata is stored in a single file called metadata.csv. This file drives all code generation and is what helps ensure inter-platform consistency.